Psychoakustische Grundlagen der Musik
Die Psychoakustik befasst sich mit der Wahrnehmung von Schall. Physikalisch gesehen entsteht Schall durch mechanische Schwingungen von festen Körpern, die eine Schallwelle, das ist eine Druckwelle in der umgebenden Luft auslösen. Von der Schallquelle ausgehend werden die benachbarten Luftmoleküle der Reihe nach immer weiter zum Schwingen gebracht. Dieser Vorgang breitet sich nach allen Richtungen mit einer Geschwindigkeit von 343 m/sec aus. Sobald die Schallwelle unser Ohr erreicht, setzt ein komplexer, mehrstufiger neuronaler Verarbeitungsprozess ein, der schließlich zu einem Hörereignis (z.B. zur Empfindung eines Tons) führt. Die Psychoakustik untersucht nun die Beziehung zwischen den physikalischen (akustischen) Eigenschaften von Schall und den damit verbundenen (ausgelösten) auditiven Empfindungen. Darüber hinaus ist die Informationsverarbeitung im auditorischen System ebenfalls Thema der Psychoakustik.
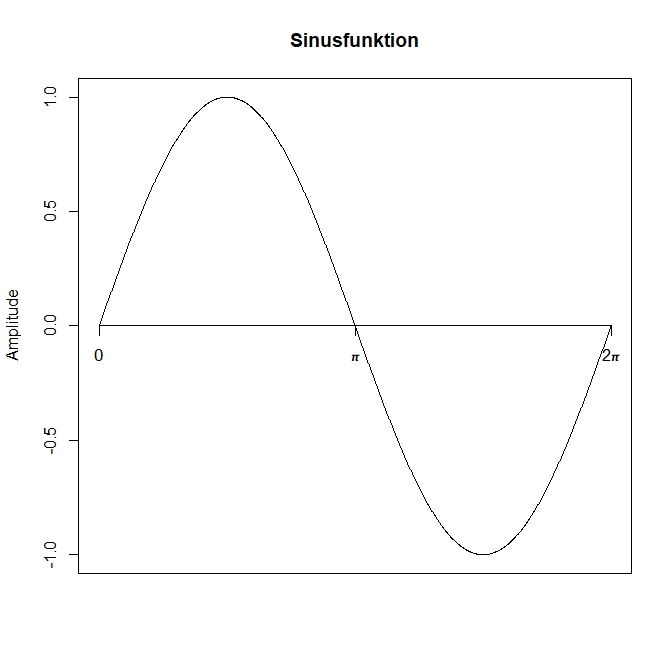
Die Schallwellen, die in der Musik betrachtet werden, sind im Normalfall periodische Wellen, d.h. deren Schwingungsform wiederholt sich immer wieder (z.B. 100 mal in der Sekunde). Die einfachste Form einer periodischen Welle ist die Sinuswelle oder auch harmonische Schwingung.
1 Sinuswellen
1.1 Die Sinusfunktion
Die Form einer Sinuswelle wird durch die Sinusfunktion beschrieben:
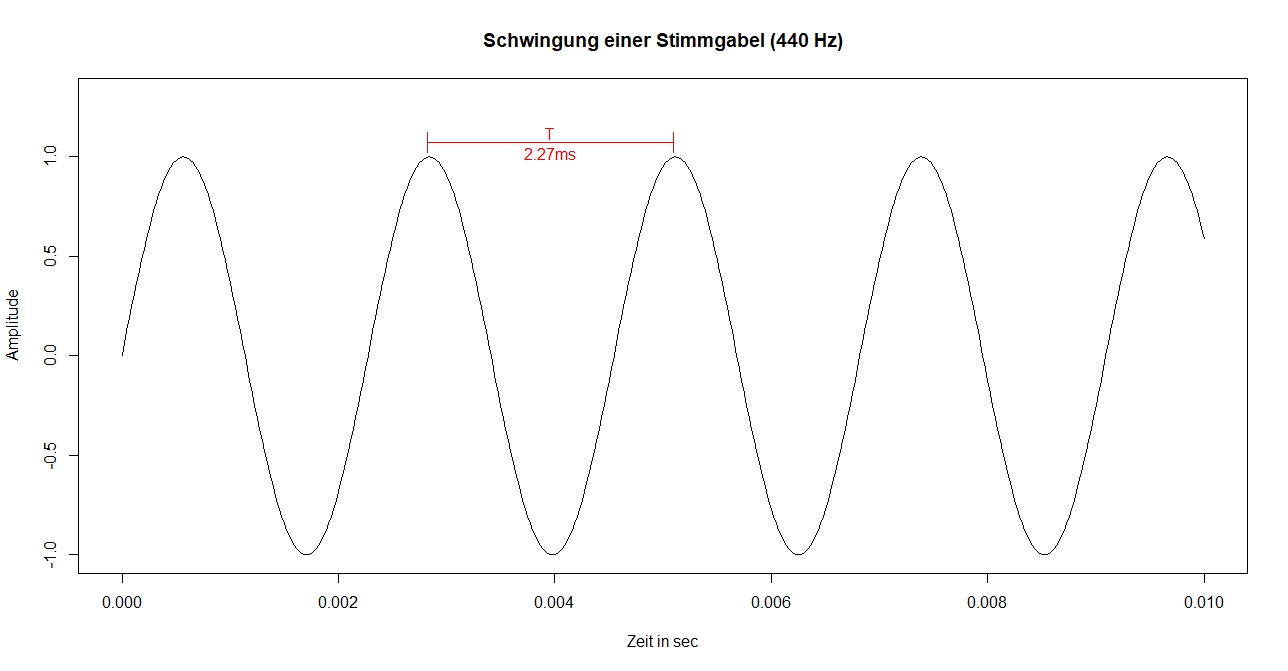
Eine Stimmgabel schwingt in Form einer Sinuswelle, d.h. wird sie angeschlagen, ist ein Sinuston zu hören.
Sinuswellen sind nicht nur die einfachste, sondern auch die wichtigste Wellenform. Sie bilden die Elementarbausteine für alle anderen periodischen Wellenformen. Auch in der Wissenschaft vom Schall spielen Sinustöne die entscheidende Rolle für das Verständnis aller einfachen und komplexen Phänomene. Sie liefern die Grundlage für die Lösung von Problemen in der Akustik und in der Musik.
1.1.1 Charakteristika einer Sinuswelle
- Frequenz (gemessen in Schwingungen pro Sekunde; Einheit: Hertz [Hz]; in Formeln meist mit f bezeichnet);
eine einzelne ganze Schwingung, bis das System wieder im gleichen Zustand ist, wird Periode genannt; die Periodendauer (meist mit T bezeichnet) hängt direkt mit der Frequenz zusammen: T=1/f, denn die Frequenz gibt ja die Anzahl der Perioden pro Sekunde an.
die Frequenz entspricht wahrnehmungspsychologisch der Tonhöhe - Amplitude (Stärke des Ausschlags; in Formeln z.B. mit a bezeichnet); die Amplitude entspricht in der Wahrnehmung der Lautstärke
- Phase (Horizontalverschiebung der Sinuswelle; in Formeln z.B. mit φ bezeichnet; die Phase spielt für das Hören normalerweise keine Rolle)
Soundbeispiele:
2 Komplexe Wellen
2.1 Obertöne
Eine Gitarrensaite schwingt nicht nur in seiner gesamten Länge auf und ab (Grundschwingung), sondern auch in ihren Teillängen 1/2, 1/3, 1/4, ... (diese bilden die Oberschwingungen).
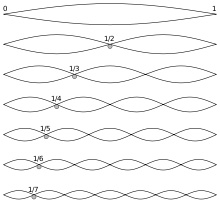
All diese Schwingungen überlagern sich zu einem komplexen Schwingungsmuster, z.B.
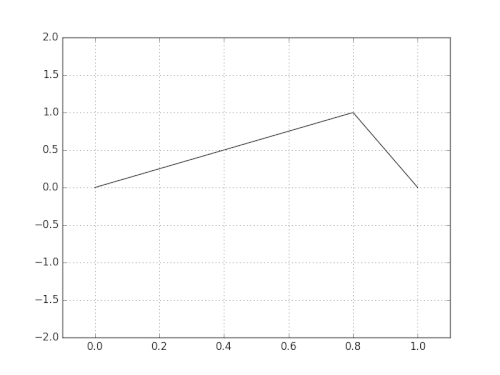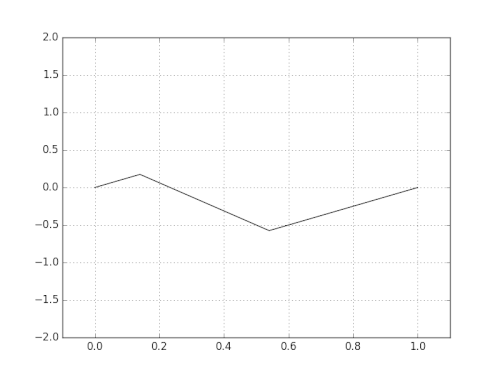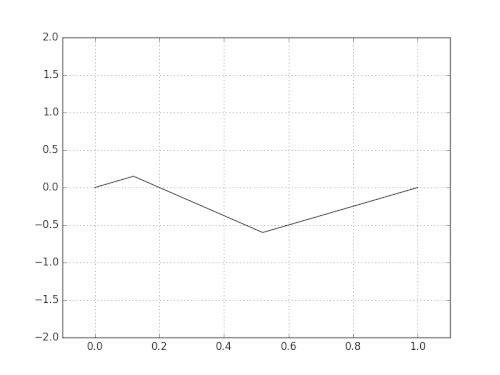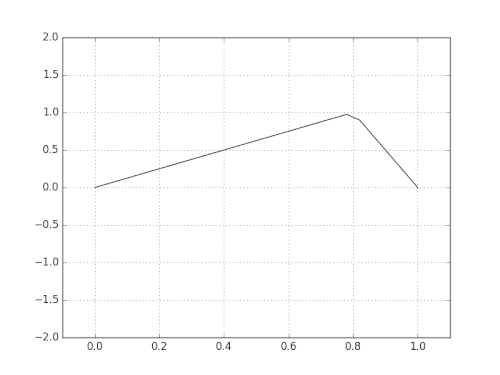
Die Grundschwingung ergibt den sog. Grundton und die Schwingungen der Teile ergeben die sogenannten Obertöne. Diese sind maßgeblich für den Klang des Instruments verantwortlich. [Übrigens bezeichnet man den Grundton mit seinen Obertönen oft auch als "Harmonische" oder "Teiltöne", d.h. der Grundton ist die erste Harmonische, der erste Oberton die zweite Harmonische usw.]
Das folgende Bild zeigt die Obertonreihe des großen A (110 Hz) bis zum 15. Oberton:

Diese Obertonreihe lässt sich folgendermaßen als Noten hinschreiben (allerdings lassen sich die höchsten Obertöne nur mehr ungefähr notieren, denn sie rücken immer enger zusammen):

2.2 Frequenzspektrum
2.2.1 Fourieranalyse
Es ist ein komplexer Ton von 200 Hz zu hören, von dem nacheinander einzelne Obertöne weggenommen und wieder hinzugefügt werden, was jeweils deutlich zu hören ist.
Generell kann jede beliebige periodische Funktion (d.h. auch jede beliebige Schallwelle) als simultane überlagerung von verschiedenen Sinuswellen dargestellt werden. Das mathematische Verfahren dafür ist die sog. "Fourieranalyse". Ein Ton eines Musikinstruments (oder eines Sängers) ist also eindeutig darstellbar als Verschmelzung von vielen Tönen, als Überlagerung eines Grundtons mit Obertönen, deren Frequenzen ganzzahlige Vielfache der Grundfrequenz (f0, Frequenz des Grundtons) sind.
Wenn all die Teiltöne im obigen Bild überlagert werden, entsteht
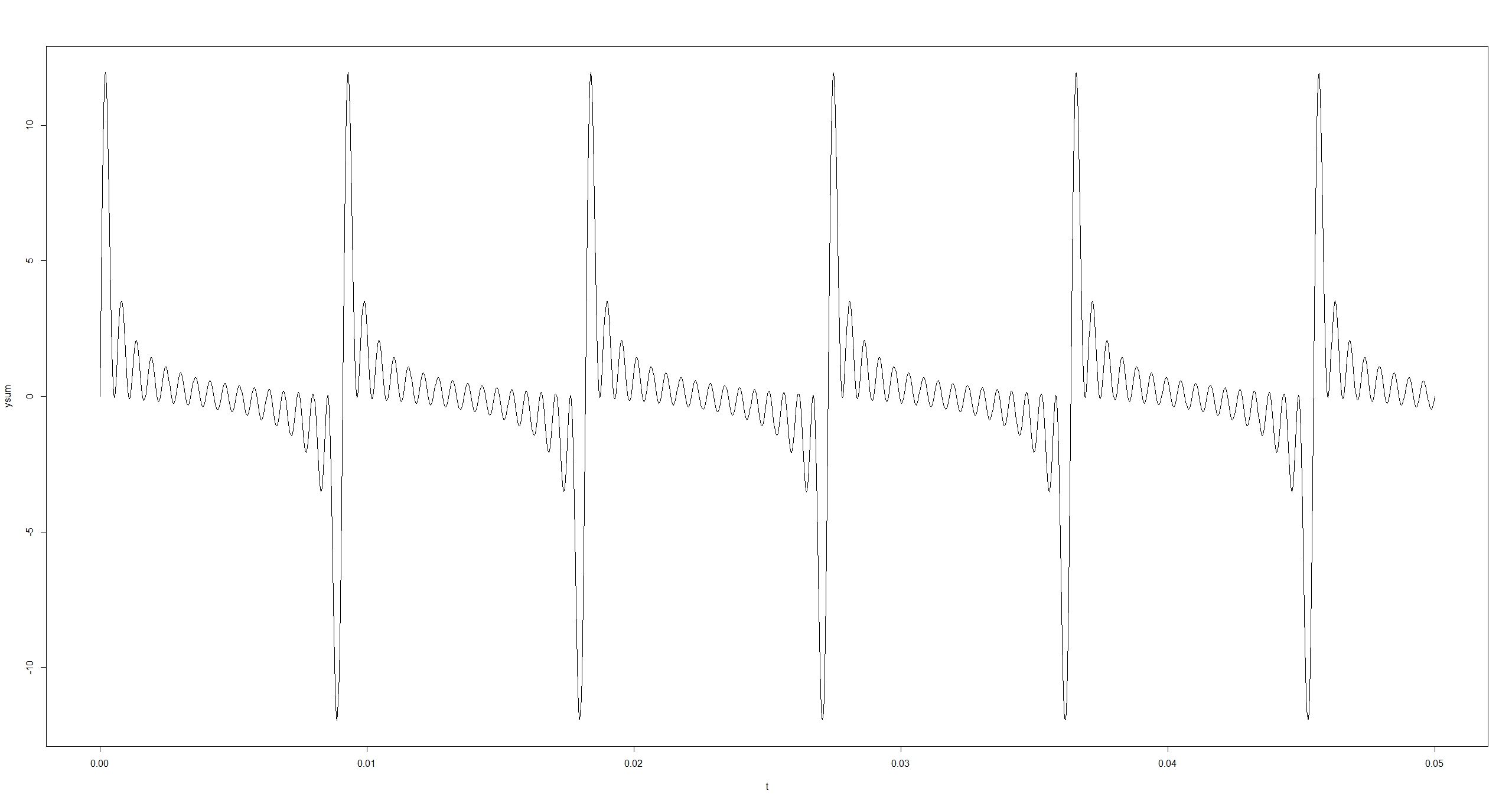
Dies ist die Darstellung der Wellenfunktion im Zeitbereich: die Amplitude wird in Abhängigkeit von der Zeit dargestellt (technisch realisierbar mit einem Oszilloskop).
Neben dieser Form der Darstellung bietet sich vornehmlich noch eine andere Darstellung der Wellenfunktion an:
die Darstellung im Frequenzbereich mit Hilfe eines Spektrogramms.
In diesem ist das sog. Frequenzspektrum dargestellt: pro Frequenz ist jeweils die Amplitude (die Stärke)
aufgetragen, mit der sie in den komplexen Klang eingeht.
Die Amplitude wird also in Abhängigkeit von den beteiligten elementaren Frequenzen dargestellt.
Im obigen Beispiel ging jeder Teilton, d.h. jede Frequenz, gleich stark in die Summe ein. Das Spektrogramm ist also:
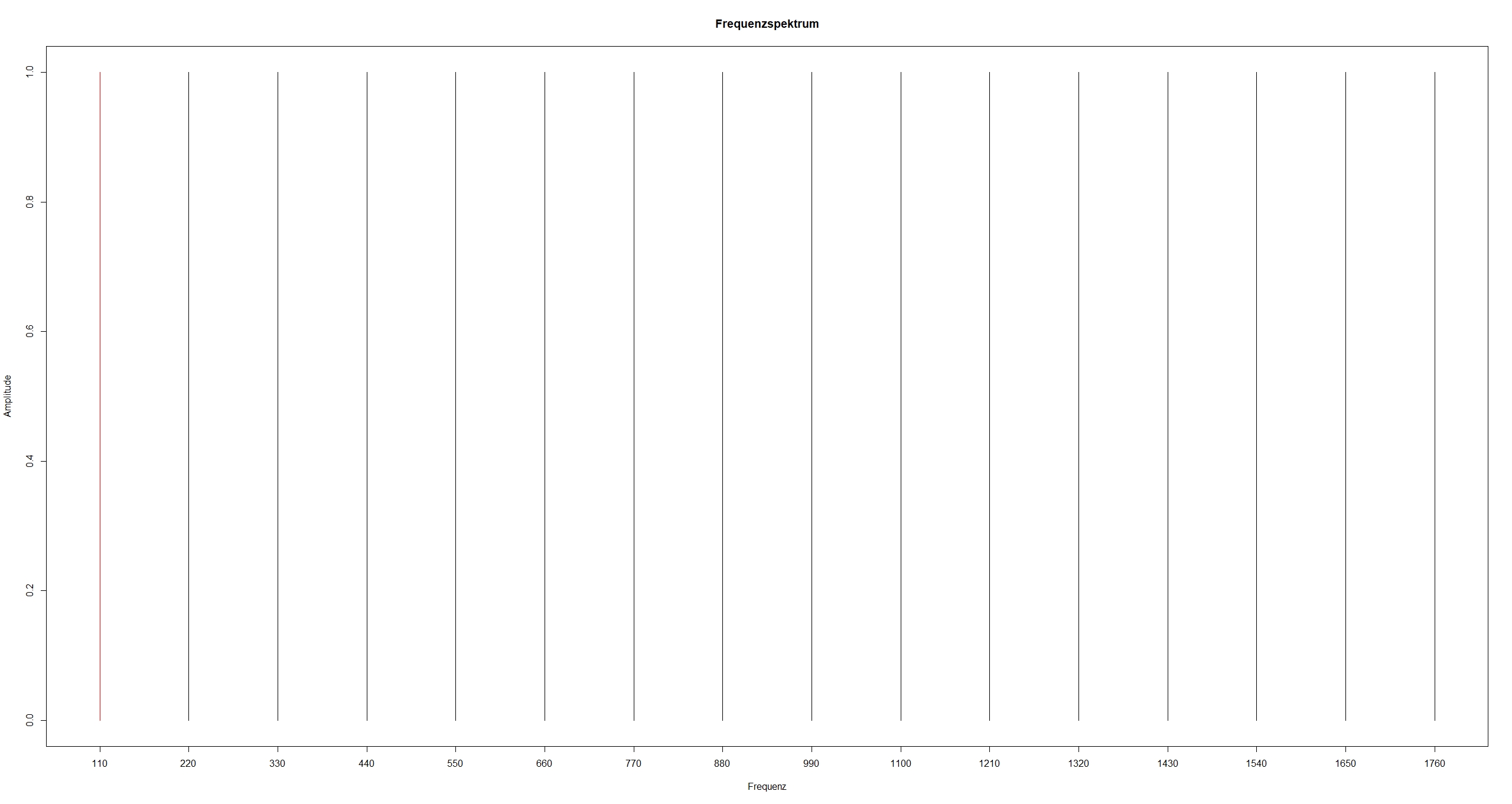
Im Gegensatz zu dem eben betrachteten extremen Beispiel haben die einzelnen Teiltöne eines Klanges normalerweise unterschiedliches Gewicht, d.h. sie gehen unterschiedlich stark in den zusammengesetzten Klang ein, z.B.
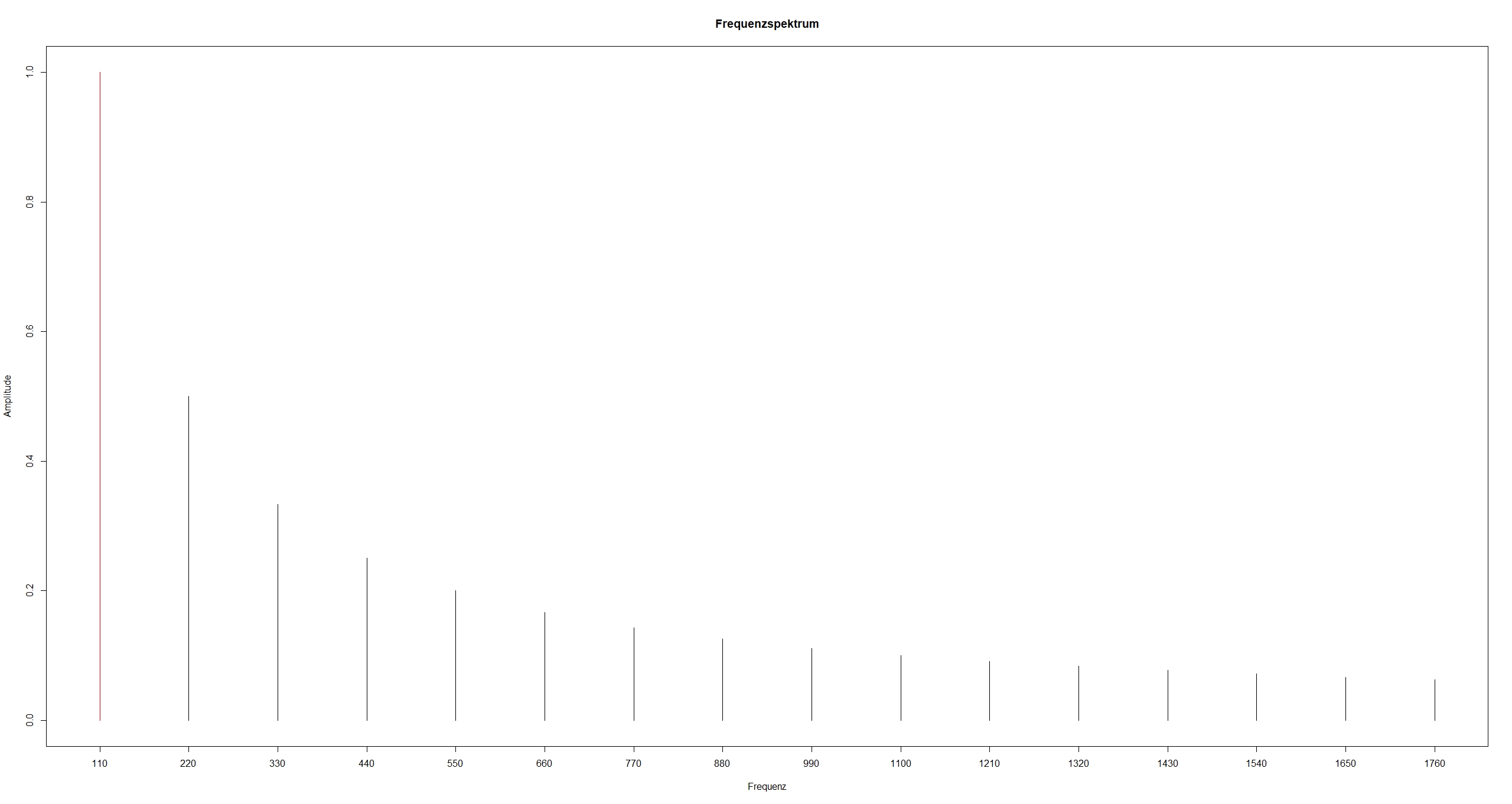
hier mit den Gewichten 1, 1/2, 1/3, 1/4, 1/5, ... . Damit ändert sich das Bild und der Klang (das Ergebnis ist die Sägezahnfunktion):
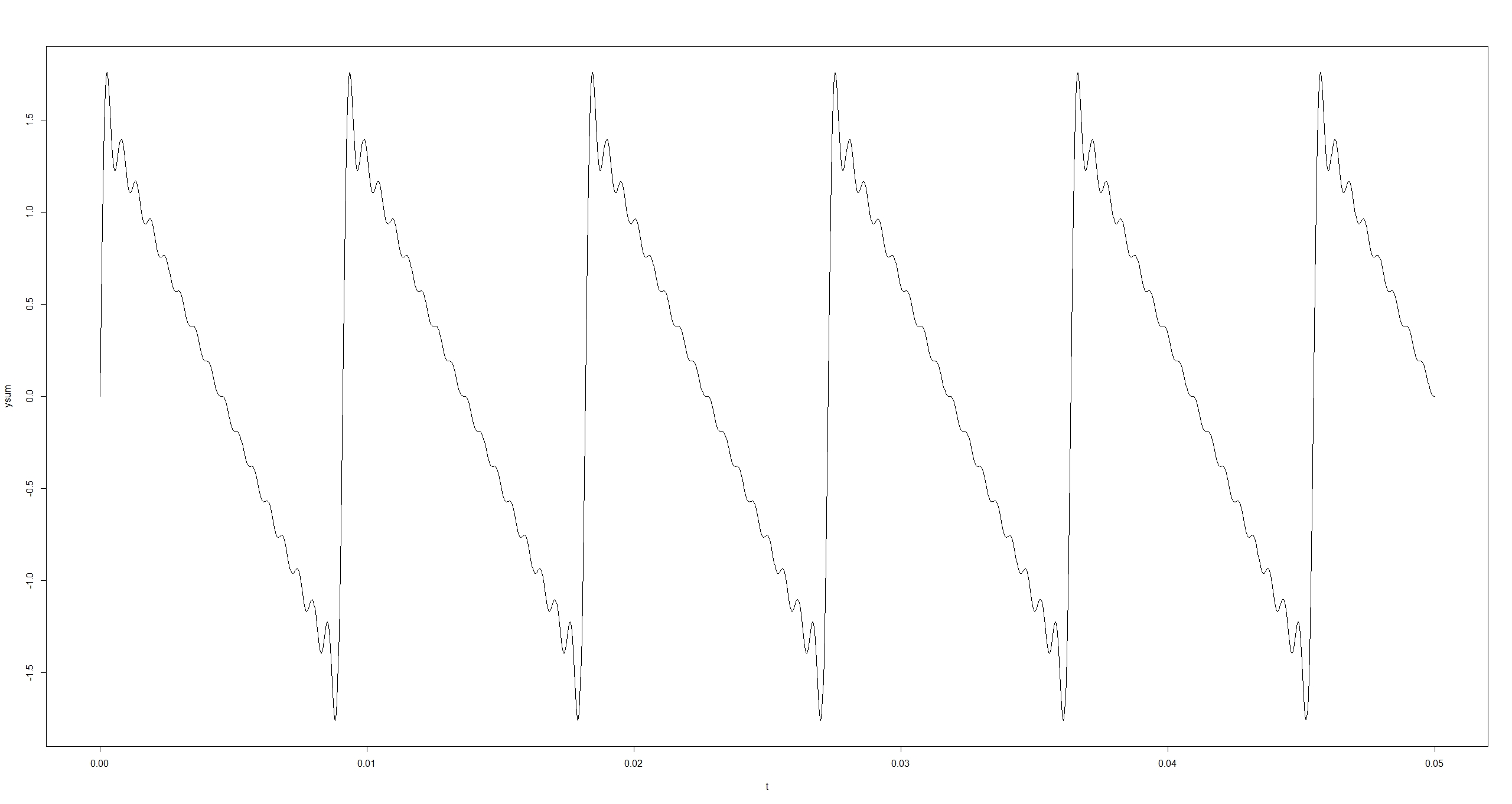
Das Frequenzspektrum spielt für die Wahrnehmung der Klangfarbe (Timbre) eine entscheidende Rolle.
Beispiel Musikinstrumente:
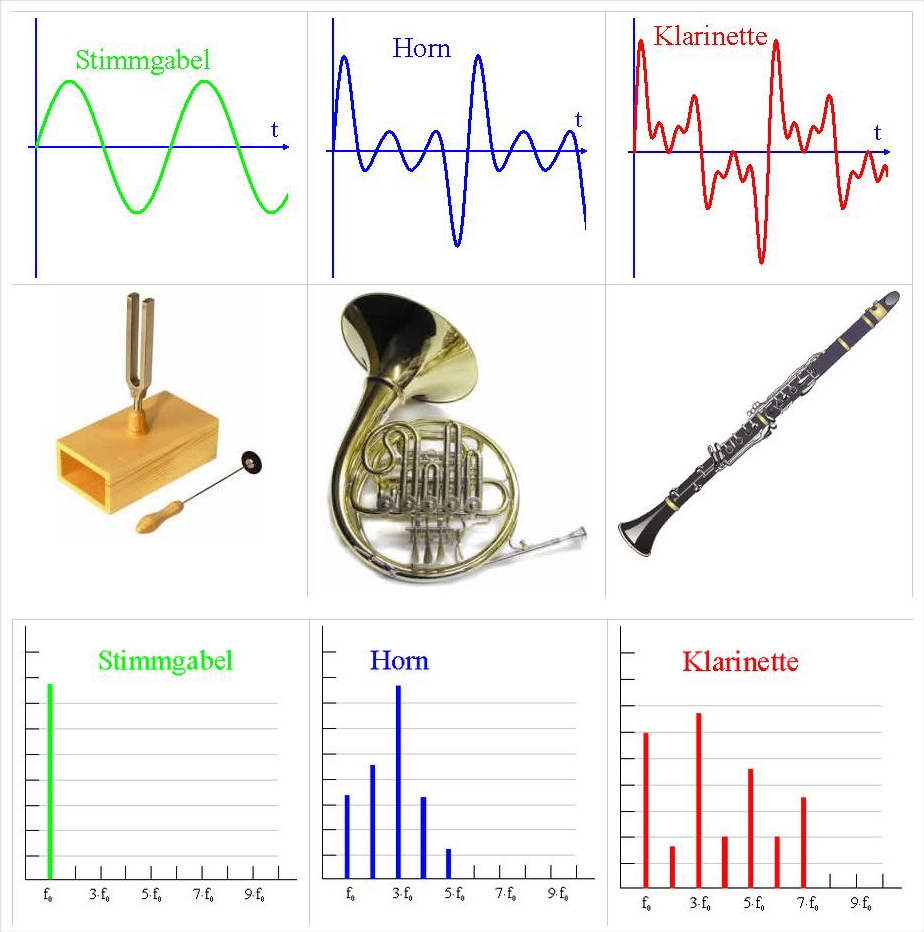
2.2.2 Ergebnis der Fourieranalyse bei einem zeitlich begrenzten Ton
In den bisherigen Beispielen betrachteten wir den Idealfall einer zeitlich unbegrenzten priodischen Funktion.
In diesem Fall liefert die Fourieranalyse ein sog. Linienspektrum,
d.h. einzelne senkrechte Linien, die genau den beteiligten Frequenzen entsprechen.
In der Praxis ist ein Ton jedoch immer von begrenzter Zeitdauer.
In diesem Fall ergibt sich dann ein Spektrum mit mehr oder weniger breiten Frequenzbändern
mit einzelnen Peaks. Deren Mittenfrequenzen liegen genau an den Stellen der beteiligten Teiltöne.
Im folgenden Beispiel ist das Spektrum eines von einem professionellen Sänger gesungenen Tones C3 (130.8 Hz) zu sehen:

2.2.3 Das Spektrum von nicht-tonalem Material
Neben Tönen und Klängen gibt es auch andere Formen von Schallereignissen, nämlich Geräusche jedwelcher Art (Rauschen, Knallen, Zischen usw.). Geräusche haben weder eine Tonhöhe noch sind irgendwelche Partialtöne erkennbar. Deshalb ist ihr Spektrum nicht diskret in Form von einzelnen Linien, sondern kontinierlich. Wir haben es hier sozusagen mit einer Summe von unendlich vielen Partialtönen zu tun, d.h. bei jeder beliebigen Frequenz ist akustische Energie vorhanden.

Bei Musikinstrumenten, beim Gesang und in der Sprache spielen neben den Tönen auch Geräusche eine wichtige Rolle, z.B. das Kratz- oder Zupfgeräusch bei Saiteninstrumenten oder die Konsonanten beim Gesang oder z.B. der Klang einer Singstimme bei Heiserkeit. Genau genommen steckt in fast jedem tonalen Ereignis auch nicht-tonales Material. Dies zeigt sich dann in einem verschmierten oder verrauschten Spektrum.
3 Intervalle, Skalen und Akkorde
3.1 Die Obertonreihe
Die (natürliche) Obertonreihe ist die Grundlage für alle nachfolgenden Ausführungen. Aus der Obertonreihe 2f0,3f0,4f0,... zu einem Grundton f0 lassen sich nämlich die folgenden einfachen Intervalle ableiten:
| Betrachtete Obertöne | Frequenzverhältnis | Intervall |
|---|---|---|
| 2f0/f0 | 2:1 | Oktave |
| 3f0/2f0 | 3:2 | Quinte |
| 4f0/3f0 | 4:3 | Quarte |
| 5f0/4f0 | 5:4 | große Terz |
| 6f0/5f0 | 6:5 | kleine Terz |
| 9f0/8f0 | 9:8 | großer(!) Ganzton |
| 10f0/9f0 | 10:9 | kleiner(!) Ganzton |
| 16f0/15f0 | 16:15 | Halbton |
Hinweise
- Neben den aufgeführten Intervallen gibt es noch weitere wie Sexten und Septimen, sowie als Trivialfall die "Prim" (Frequenzverhältnis 1:1).
- Zusätzlich gibt es zu allen Intervallen noch abgewandelte Formen: verminderte und übermäßige Intervalle.
- Es gibt zwei verschiedene Ganztöne (Frequenzverhältnis 9:8 und 10:9).
- Die Teiltöne 2f0, 4f0, 8f0, 16f0 32f0 usw. sind die Oktaven zum Grundton f0.
- In einem Dur-Dreiklang (Grundton+Terzton+Quintton) besteht das Frequenzverhältnis: 4:5:6.
- Für den Zusammenklang von Tönen gilt allgemein: je einfacher die Frequenzverhältnisse sind, desto sauberer ist das Ergebnis. Leider lässt sich dies nicht immer erreichen, so dass man zuweilen Kompromisse eingehen muss.
- Intervalle kann man aneinanderhängen ("aufeinanderstapeln")
d.h. addieren bzw. subtrahieren (Beispiel: Oktave - Quinte = Quarte).
Die entsprechenden Frequenzverhältnisse müssen dabei multipliziert bzw. dividiert werden (Beipiel: 2/1 / 3/2 = 4/3).
Mit Hilfe solcher Rechenoperationen lassen sich neue Intervalle ableiten.
Beispiele:- Große Septime (15:8): Quinte + große Terz (3/2 * 5/4)
- Große Sexte (5:3): Quarte + große Terz (4/3 * 5/4) oder Quinte + kleiner Ganzton (3/2 * 10/9)
- Die große Terz (5:4) ergibt sich übrigens auch aus: großer Ganzton + kleiner Ganzton (9/8 * 10/9)
- Den großen Ganzton (9:8) bekommt man aus 2 Quinten minus 1 Oktave (3/2 * 3/2 / 2/1).
3.2 Tonleitern
Aus dem Tonvorrat der ersten Obertöne sowie nach dem Prinzip der einfachen Frequenzverhältnisse lässt sich von jedem Grundton aus eine Tonleiter aufbauen, z.B. die Dur-Skala. Nimmt man als Grundton z.B. den Ton C, so erhält man die "reine" C-Dur-Tonleiter mit folgendem Aufbau (Hinweis: im Englischen wird der Ton H mit B bezeichnet):
.jpg)
Hinweise
- Wegen der Oktaväquivalenz gilt eine Tonleiter für jeden Oktavraum im gesamten Tonumfang (z.B. kann ein und dasselbe Lied in verschiedenen Stimmlagen gesungen werden).
- Man beachte, dass das Intervall von der ersten zur zweiten Stufe ein großer Ganzton ist, von der zweiten Stufe zur dritten hingegen ein kleiner Ganzton.
3.3 Stimmung(en)
- Die mit den obigen Frequenzverhältnissen konstruierte Tonleiter definiert die sog. "reine Stimmung" (engl. "just temperament"; übrigens wird für Stimmung auch der Begriff "Temperatur" verwendet).
- Eine Alternative zur reinen Stimmung ist die sog. "pythagoräische Stimmung".
Pythagoras hat für seine Tonleiter lediglich Quinten und Oktaven verwendet.
Durch geeignete Operationen mit diesen Grundintervallen kann jeder Ton innerhalb einer 12-stufigen Oktave erreicht werden.
Dabei ergibt sich jedoch ein Problem:
12 Quinten übereinander ergeben nach den bisherigen Ausführungen etwas anderes als 7 Oktaven übereinander:
im Quintenzirkel C→G→d→a→e'→h'→fis''→cis'''→gis'''→dis''''→ais''''→eis'''''→his''''' landet man am Ende beim his''''' und nicht beim c'''''',
denn es gilt (3/2)12 > (2/1)7 d.h. 129.75 > 128 (Faktor: 1.01364). Dieser Unterschied ist übrigens das "pythagoräische Komma".
Anhören: 7 Oktaven - 12 Quinten 🔈 - Der Vorteil der reinen Stimmung liegt in der Reinheit des Klanges, der Nachteil hingegen liegt in der fehlenden Möglichkeit für Modulationen (Tonartwechsel).
Beispiel: in C-Dur ist das Intervall von G nach A ein kleiner Ganzton, in G-Dur aber ein großer Ganzton, d.h. es muss anders intoniert werden.
Dies ist bei frei intonierbaren Instrumenten und beim Gesang möglich, nicht jedoch bei Instrumenten mit fest eingestellten Frequenzen (wie z.B. beim Klavier).
Das Problem ergibt sich also beim gemeinsamen Musizieren mit Tasteninstrumenten.
Klangbeispiel für eine Modulation:
- In der Geschichte der Musik gab es unzählige Lösungen, einen Kompromiss zu finden zwischen der Reinheit des Klanges und der Möglichkeit für Modulationen.
- Unbegrenzte Modulationsmöglichkeiten, aber leider zu Lasten des reinen Klanges, bringt die heute allgemein verbreitete gleichstufige Stimmung: man teilt die Oktave (im logarithmischen Maßstab) einfach in zwölf gleiche Intervalle (Halbtöne) ein. Daraus ergibt sich für den Halbton ein Frequenzverhältnis von 21/12:1 (12tel Wurzel von 2 zu 1). Das Frequenzverhältnis eines Intervall von n Halbtönen ergibt sich dann einfach aus 2n/12:1. Damit sind alle Intervalle außer der Oktave mehr oder weniger unrein.
- Warum verwendet man den logarithmischen Maßstab? Begründung: unser Gehör empfindet die Frequenzen - wie auch die Lautstärke - logarithmisch und addiert Intervalle (zum Beispiel: große Terz + kleine Terz = Quint). Bei der Centangabe (s.u.) werden die Intervalle ebenfalls addiert - im Gegensatz zur Multiplikation von Frequenzverhältnissen.

3.4 Cent-Skala
- Um verschiedene Stimmungen und Töne bequem miteinander vergleichen zu können, wurde die sog. Cent-Skala erfunden: man teilt die Oktave (im logarithmischen Maßstab) in 1200 gleiche Mikrointervalle ein. Ein Cent entspricht also dem Frequenzverhältnis 21/1200, also 1.0005778.
- 100 Cent entsprechen einem Halbton in der gleichstufigen Stimmung.
- Umrechnung eines Intervalls zwischen zwei Tönen mit den Frequenzen f1 und f2
(Frequenzverhältnis p = f1/f2) in Cent c:
c = 1200 ⋅ 3.322038403 ⋅ log10(p) (Hinweis: 1/log10(2) = 3.322038403) - Umrechnung von c Cent in das entsprechende Frequenzverhältnis p:
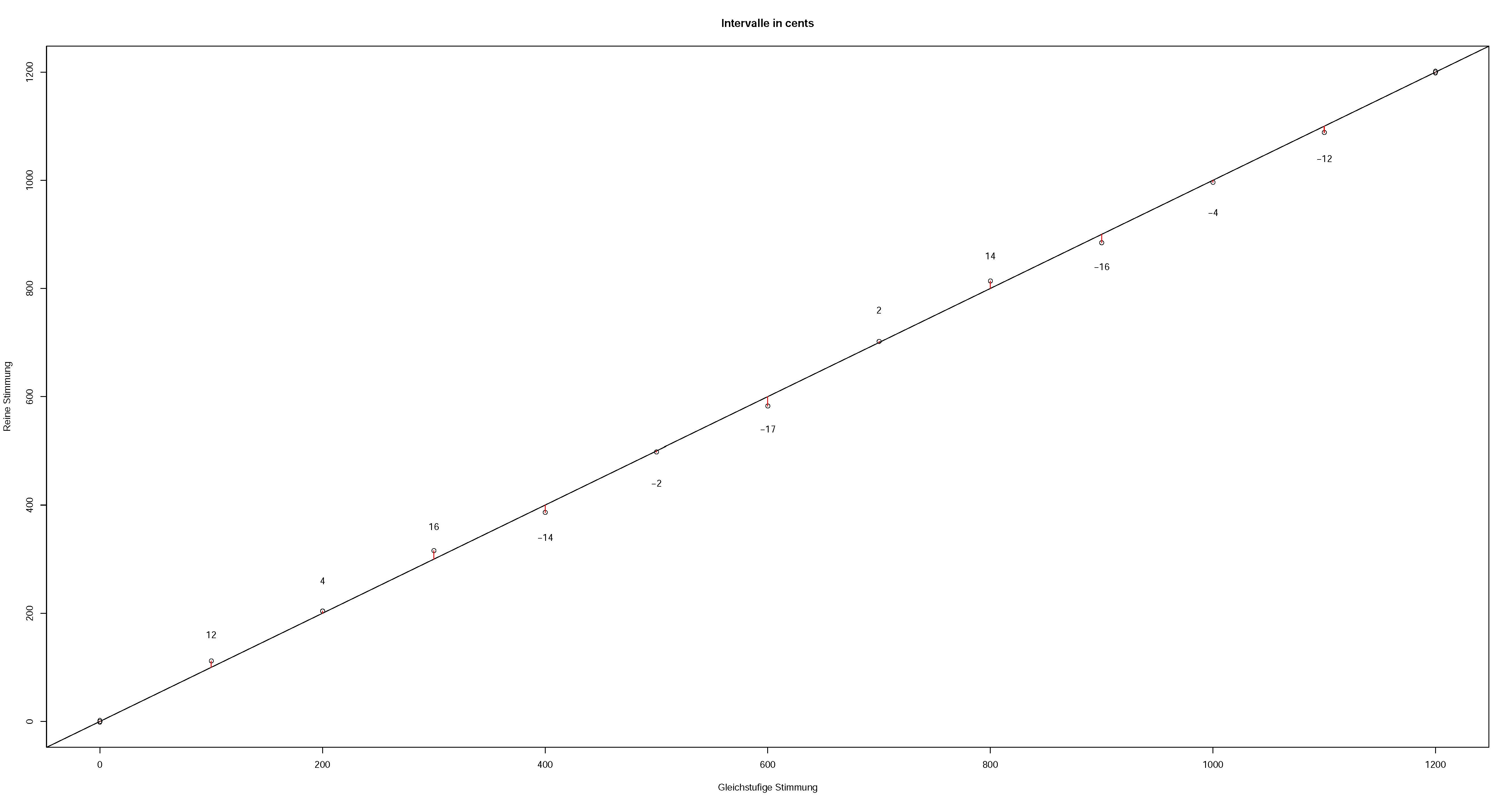
p = 2c/1200 = 1.0005778c - In der folgenden Graphik sieht man nun, um wieviel Cents die gleichstufige Tonleiter von der reinen abweicht:
Im folgenden Klangbeispiel ist die A-Dur Tonleiter (ab 440 Hz) zuerst in der reinen Stimmung zu hören, dann in der gleichstufigen und am Ende sind beide überlagert, so dass man die Unterschiede gut hören kann: Anhören 🔈
- Der Unterschied zwischen einem kleinen und einem großen Ganzton beträgt 9/8 / 10/9 = 81/80 (21.51 Cent). Dies ist das sog. "syntonisches Komma" (übrigens: das oben erwähnte pythagoräische Komma beträgt 23.46 Cent). Klangbeispiel zum Vergleich der Ganztöne: Anhören 🔈
- Centwerte der Tonleiter in der gleichstufigen und in der reinen Stimmung:
C D E F G A H C 0 200 400 500 700 900 1100 1200 0.0 203.9 386.3 498.0 702.0 884.4 1088.3 1200.0
3.5 Konsonanz/Dissonanz
Erklingen zwei Töne gleichzeitig, so kann ihr Zusammenklang konsonant oder dissonant sein, anhängig vom Intervall, das sie bilden. Allerdings gibt es zwischen den beiden Extremen graduelle übergänge. Erwähnt sei noch, dass sich die Auffassung über Konsonanz und Dissonanz im Verlaufe der Musikgeschichte auch gewandelt hat (so galten im Mittelalter die Terzen und Sexten als dissonant).
Allgemein kann man sagen: je einfacher das Schwingungsverhältnis von zwei Tönen ist, desto mehr gemeinsame Obertöne verbinden sie und umso konsonanter wird das Intervall wahrgenommen.
3.5.1 Schwebung
Erklingen zwei Töne mit leicht unterschiedlichen Frequenzen (f1≈f2), so tritt eine sog. Schwebung auf. Dann hört man einen Ton der mittleren Frequenz, der in der Lautstärke schwankt, und zwar in der Frequenz |f1-f2| (Schwebungsfrequenz).
Die Schwebung beim Hör-Vergleich der Ganztöne (s.o.) sieht man deutlich in der folgenden Graphik:
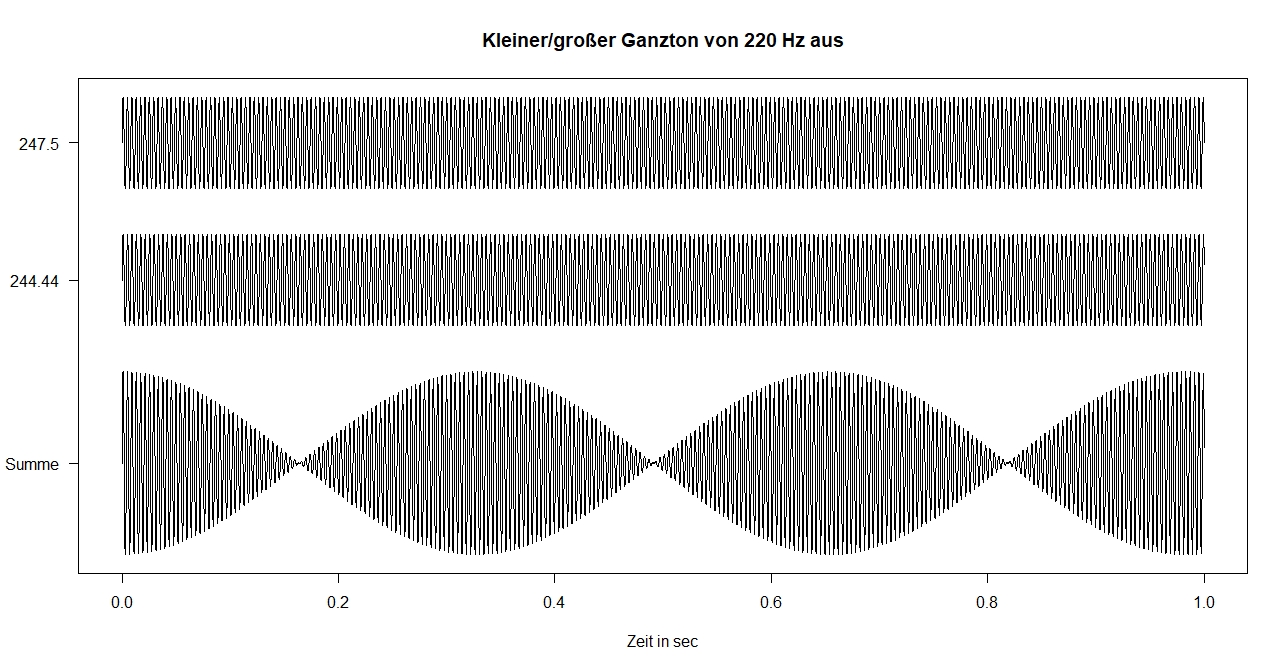
Beim obigen Klangbeispiel der A-Dur Tonleiter in verschiedenen Stimmungen waren übrigens die Schwebungsfrequenzen:
| a' | h' | cis'' | d'' | e'' | fis'' | gis'' | a'' |
|---|---|---|---|---|---|---|---|
| 0.00 | 1.12 | 4.37 | 0.66 | 0.74 | 6.66 | 5.61 | 0.00 |
Schwebungsfrei, d.h. identisch bei beiden Stimmungen, sind nur die Prim und die Oktave. Bei Terz, Sexte und Septime ist die Schwebung recht groß, d.h. bei diesen Intervallen gibt es relativ große Unterschiede zwischen der gleichstufigen und der reinen Stimmung.
In unseren bisherigen Beispielen wurden Sinustöne verwendet. Hier treten bei unsauber intonierten Primen Schwebungen auf. Bei einer unsauber intonierten Oktave von Sinustönen entsteht so etwas:
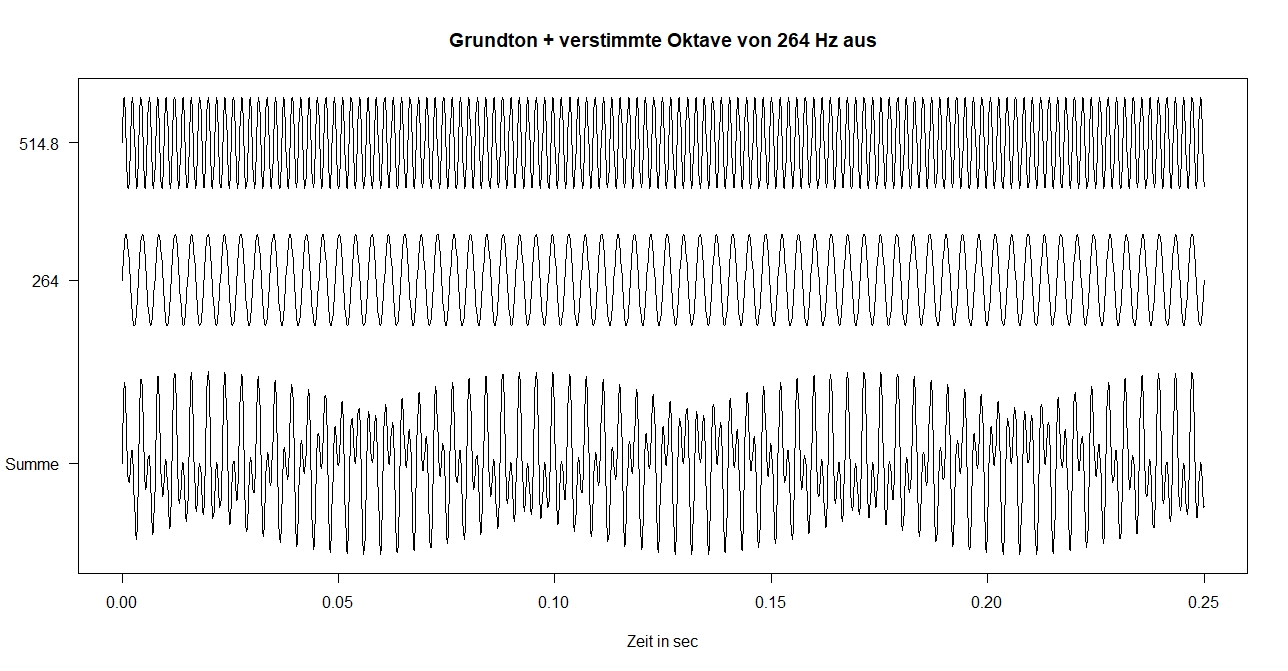
Nimmt man allerdings Klänge wie im Normalfall (d.h. Töne mit Obertönen), so können auch in den Obertönen Schwebungen auftreten und den Zusammenklang zusätzlich zu den Grundtönen negativ beeinflussen.
Weitere Klangbeispiele:
- Unreine Oktave Anhören 🔈
- Unreine Quinte Anhören 🔈
- Quinten in verschiedenen Oktavlagen: gleichstufig: Anhören 🔈 — rein: Anhören 🔈
- Terzen: pythagoräisch: Anhören 🔈 — rein: Anhören 🔈
- Terzen mit vielen Obertönen: gleichstufig: Anhören 🔈 — rein: Anhören 🔈
- Schwebung bei einer kleinen Sekunde: Anhören 🔈
- Unreine Primen (auch mit Obertönen): Anhören 🔈 — Anhören 🔈 — Anhören 🔈
-
Vollkadenz:

3.5.2 Rauigkeit
Erhöht sich der Frequenzunterschied der beiden Töne, so vermag das Ohr den immer schneller werdenden Lautstärkeschwankungen nicht mehr zu folgen,
und man vernimmt einen Ton rauer Klangfärbung, der sich bei weiterer Vergrößerung der Frequenzdifferenz in zwei Einzeltöne aufspaltet.
Beispiele zu Schwebungen und Rauigkeit mit Sinustönen:
-
f1 = 400 Hz, f2 = 403 Hz:
 Anhören 🔈 (erst Einzeltöne, dann Schwebung von 3 Hz)
Anhören 🔈 (erst Einzeltöne, dann Schwebung von 3 Hz)
-
f1 = 400 Hz, f2 = 410 Hz:
 Anhören 🔈 (erst Einzeltöne, dann Schwebung von 10 Hz)
Anhören 🔈 (erst Einzeltöne, dann Schwebung von 10 Hz)
-
f1 = 400 Hz, f2 = 401 Hz:
 Anhören 🔈 (erst Einzeltöne, dann Schwebung von 1 Hz)
Anhören 🔈 (erst Einzeltöne, dann Schwebung von 1 Hz)
-
f1 = 400 Hz, f2 = 403 Hz:
 Anhören 🔈 (Schwebung)
Anhören 🔈 (Schwebung)
-
f1 = 400 Hz, f2 = 440 Hz:
 Anhören 🔈 (Rauigkeit)
Anhören 🔈 (Rauigkeit)
-
f1 = 400 Hz, f2 = 600 Hz:
 Anhören 🔈 (zwei getrennte Töne)
Anhören 🔈 (zwei getrennte Töne)
-
Ein Sinuston von 500 Hz wird von einem zweiten Sinuston überlagert, der den Frequenzbereich von 500 bis 700 Hz durchfährt:
f1 = 500 Hz, f2 = 500→700 Hz: Anhören 🔈 (Schwebung→Rauigkeit→getrennte Töne)
Anhören 🔈 (Schwebung→Rauigkeit→getrennte Töne)
4 Die menschliche Stimme
4.1 Die Klangerzeugung
Für eine Klangerzeugung sind immer drei Komponenten notwendig:
- MOTOR: erzeugt die Energie für die Entstehung des Klangs
- VIBRATOR: erzeugt die primäre Schallwelle
- RESONATOR: verstärkt und filtert den primären Schall
- Atmung
- Kehlkopf mit den Stimmlippen
- Ansatzrohr
1. Die Atmung sorgt für den zur Tonbildung notwendigen Luftstrom, um die Stimmbänder in Schwingung zu versetzen.
2. Die Tonbildung im Kehlkopf kommt durch den Ausatemstrom und zwar durch den sog. Bernoulli-Effekt zustande. Zunächst entsteht unterhalb der geschlossenen Stimmlippen durch den Atemstrom ein Überdruck. Dadurch werden die Stimmlippen auseinander gedrängt, und die Luft entweicht. Damit entsteht aber zwischen den Stimmlippen ein Unterdruck mit Sogwirkung, wodurch die Stimmlippen sich wieder schließen. Dieser gesamte Vorgang wiederholt sich periodisch immer wieder, es entsteht also ein pulsierender Strom von Luftpartikeln, d.h. eine Schallwelle. Dieser sog. Primär- oder Kehlkopfton klingt eher wie ein raues, schnarrendes Geräusch, letztlich eine komplexe Schwingung mit einem reichhaltigen Spektrum, d.h. mit einem Grundton und vielen Obertönen. Die Grundfrequenz dieser Schwingung entspricht der Tonhöhe des Tones. Die Anatomie der Stimmlippen ist übrigens entscheidend für die Stimmlage eines Sängers: hohe Stimmen haben kürzere und dickere Stimmlippen, tiefe Stimmen längere und schmalere.
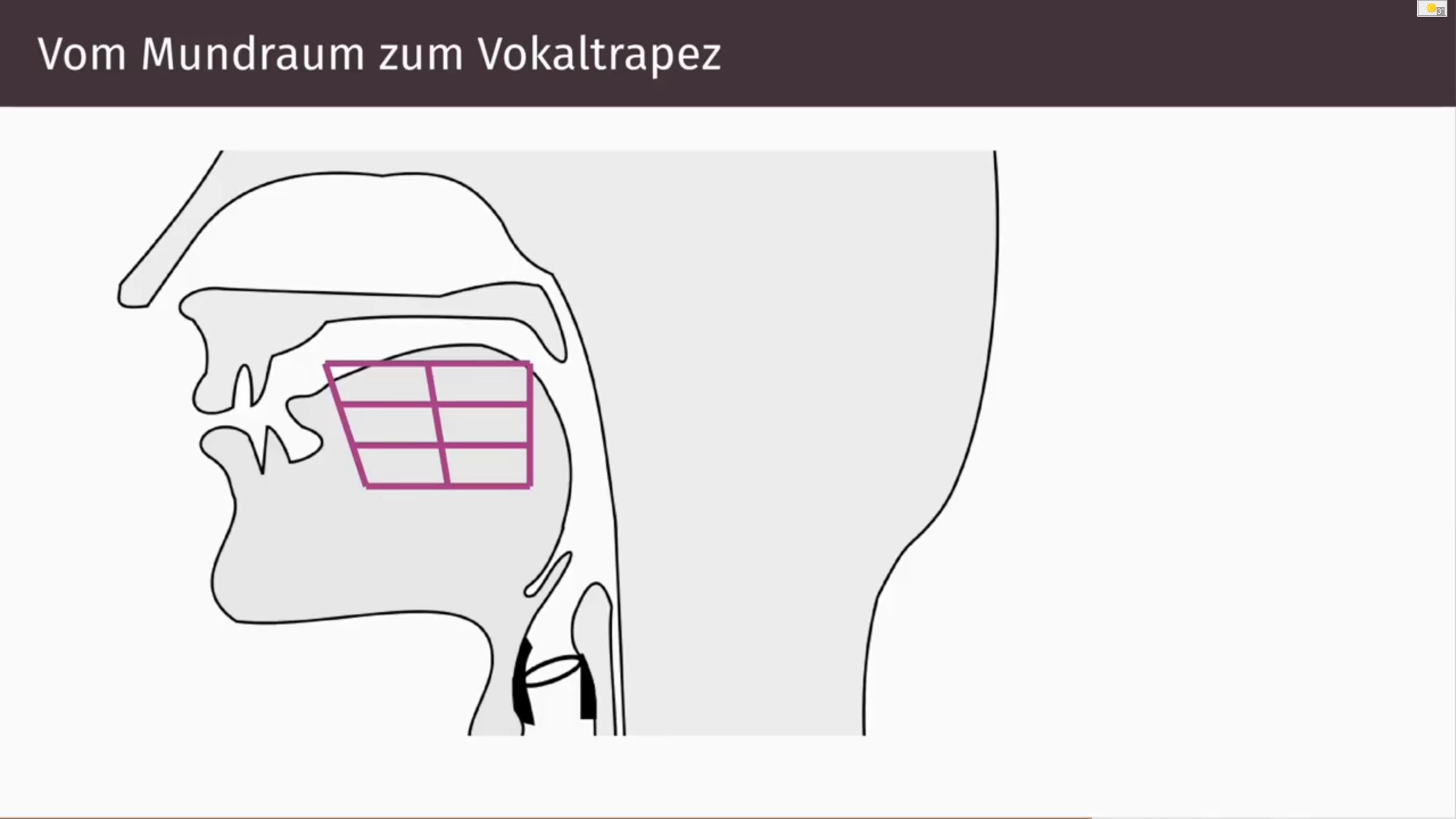
3. Das Ansatzrohr bildet den Resonanzraum für die Stimme und ist für die Lautbildung entscheidend. Hier wird der Primärton gefiltert, verstärkt und zu Lauten geformt. Das Ansatzrohr liegt oberhalb des Kehlkopfs und besteht aus: Rachenraum, Mundraum und Nasenraum. Seine Größe, Form und Beschaffenheit ist bei jedem Menschen unterschiedlich, und deshalb klingt auch jede Stimme einzigartig. Rachenraum und Mundraum bilden den sog. "Vokaltrakt". Er ist ein in Form und Größe veränderlicher Resonanzraum. Bei der Lautbildung sind also Zunge, Lippen, Zähne, Gaumen und Rachen, beteiligt. Der Nasenraum schließlich ist im Volumen zwar unveränderlich, spielt aber ebenfalls für die Resonanzbildung eine Rolle.
Die Eigenschaften eines Tons hängen von den verschiedenen Funktionsbereichen ab:
- Die Lautstärke eines Tons wird hauptsächlich durch die Kraft des Ausatemstromes aus der Lunge erzeugt.
- Die Tonhöhe wird durch die Anatomie und den Spannungszustand der Stimmlippen bestimmt.
- Die Klangfarbe hingegen wird einerseits durch die Anatomie der Resonanzräume, andererseits durch deren veränderliche Form erzeugt.
4.2 Vokale und Formanten
4.2.1 Frequenzspektrum der Vokale
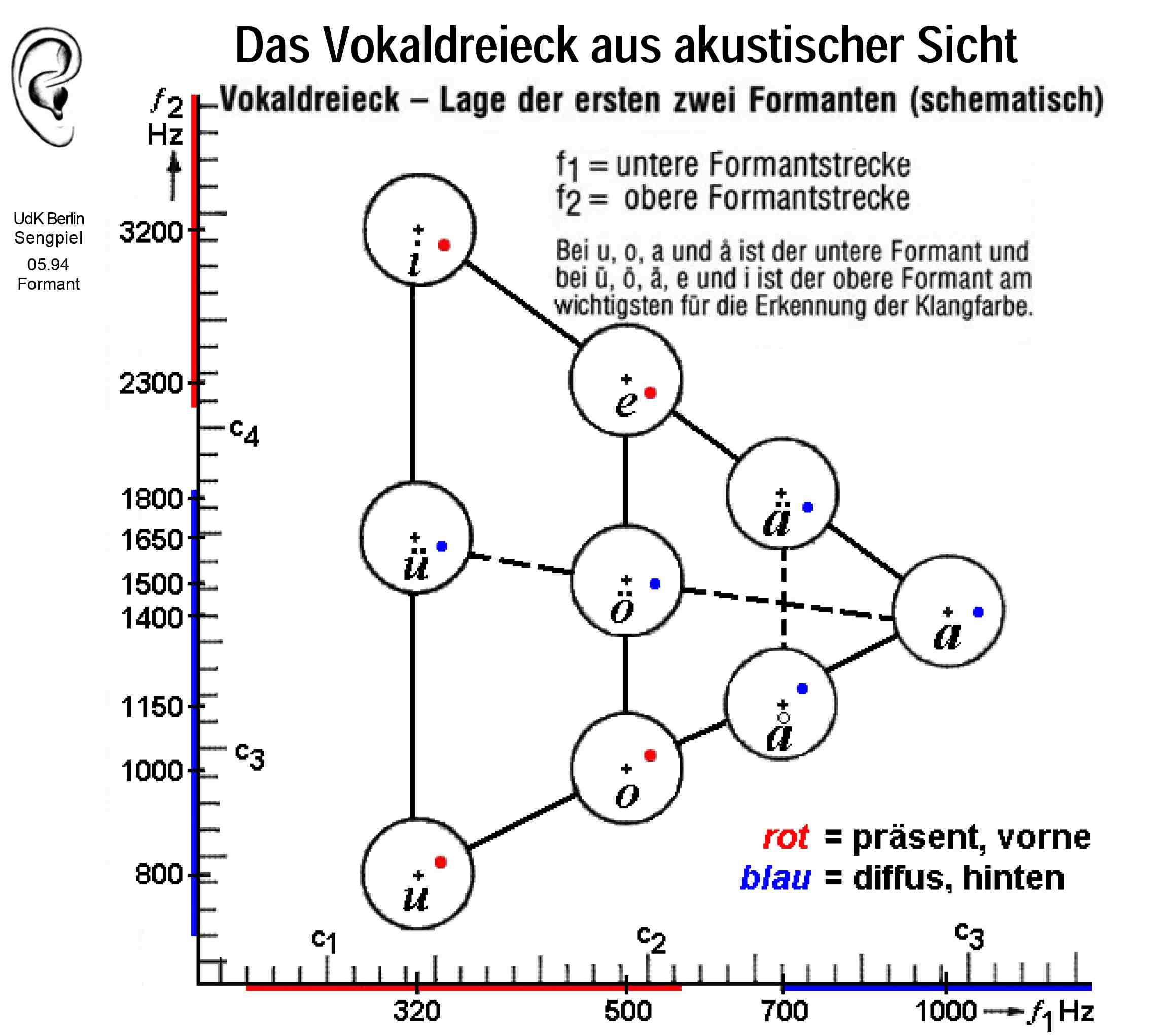
Die für den Gesang wichtigsten Laute sind die Vokale. Diese werden im Vokaltrakt erzeugt. Dabei werden aus dem Primärton bestimmte Frequenzen (Obertöne) verstärkt und andere gedämpft, d.h. das Spektrum des Primärtons wird mehr oder weniger stark verändert. Das Resultat ist das Resonanzspektrum, das ausgeprägte Berge und Täler aufweist. Die akustische Energie konzentriert sich dabei auf einzelne dominierende Frequenzbereiche ("Frequenzbänder"), d.h. es entstehen dort die "Berge". Von diesen Frequenzbändern gibt es mehrere, grob geschätzt erhält man ungefähr alle 1000 Hz ein solches Band. Diese Frequenzbänder nennt man Formanten. Das sind also jene Frequenzbereiche, bei denen die relative Verstärkung am höchsten ist. Die Formanten werden üblicherweise mit F1, F2, F3 usw. bezeichnet.
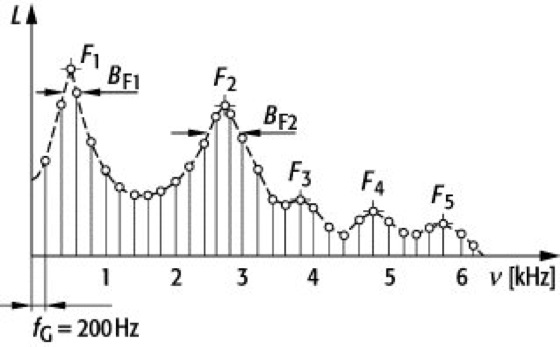
Die Formanten spielen eine wesentliche Rolle bei der Unterscheidung der Vokale. Vor allem die ersten beiden Formanten sind dabei von ausschlaggebender Bedeutung. Diese bezeichnet man auch als "Vokalformanten". Die folgende Tabelle zeigt die Frequenzzentren von F1 und F2 für die deutschen Vokale:
| Vokal | Formant F1 | Formant F2 |
|---|---|---|
| U | 320 Hz | 800 Hz |
| O | 500 Hz | 1000 Hz |
| å | 700 Hz | 1150 Hz |
| A | 1000 Hz | 1400 Hz |
| ö | 500 Hz | 1500 Hz |
| ü | 320 Hz | 1650 Hz |
| ä | 700 Hz | 1800 Hz |
| E | 500 Hz | 2300 Hz |
| I | 320 Hz | 3200 Hz |
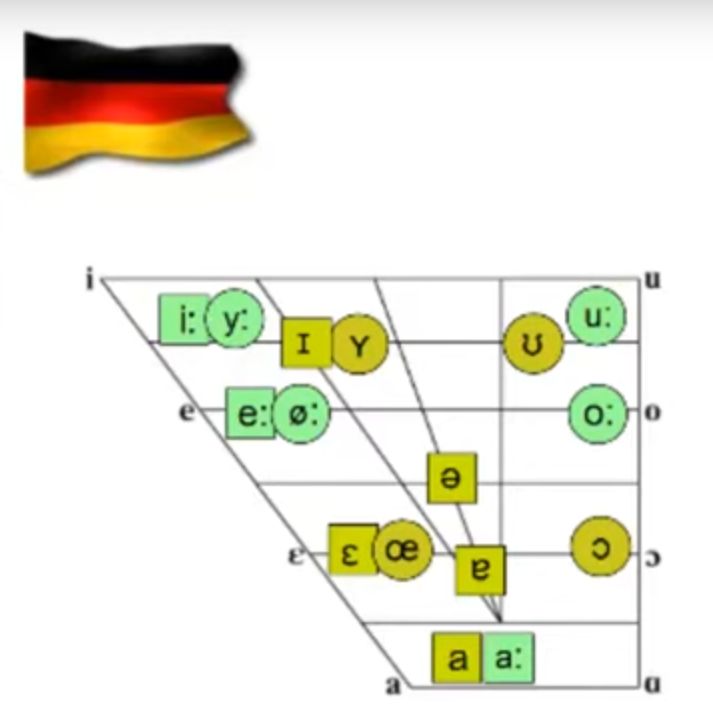
Für die englischen Vokale ergibt sich ein ähnliches, aber nicht identisches Bild:
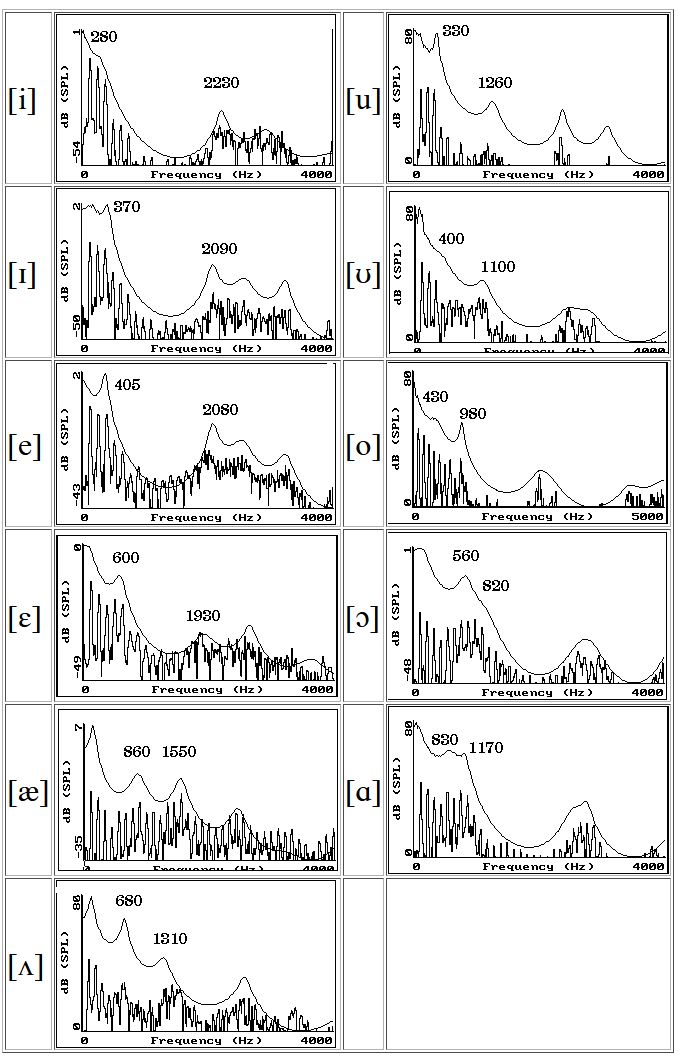
Aus diesen Diagrammen kann man eine Tabelle erstellen:

Diese Daten lassen sich auch in einem zweidimensionalen Koordinatensystem darstellen:
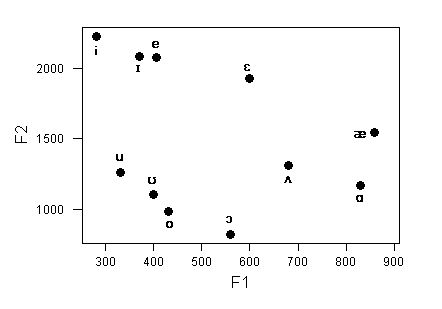
Eine etwas idealisierte Darstellung der ersten beiden Vokalformanten zeigt das sog. Vokaldreieck:
4.2.2 Erzeugung der Vokale
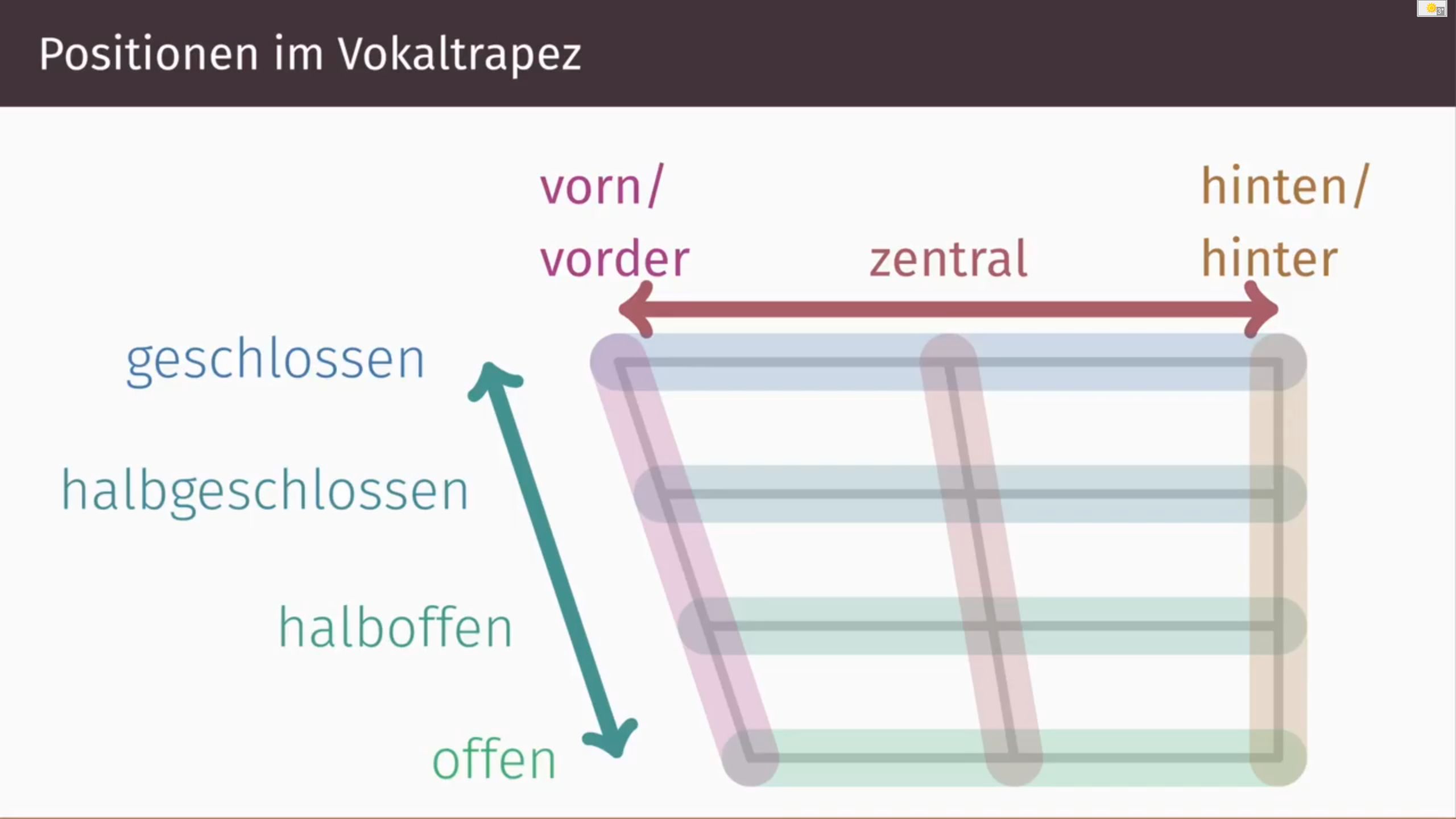
Für die Produktion der Vokale ist (neben den Lippen) in erster Linie die Zunge zuständig. Je nach Position der Zunge (hoch/tief und vorne/hinten) ergeben sich verschiedene Werte für die ersten beiden Formanten und damit auch verschiedene Vokale:
- Die Frequenz des ersten Formanten hängt von der Höhe der Zunge (flach oder hoch) ab:
- Zunge tief --> F1 hoch --> offene Vokale
- Zunge hoch --> F1 niedrig --> geschlossene Vokale
- Die Frequenz des zweiten Formanten schließlich ist abhängig von der Position der Zunge (vorne oder hinten):
- Zunge vorne --> F2 hoch --> vordere Vokale
- Zunge hinten --> F2 niedrig --> hintere Vokale
4.2.3 Der Sängerformant
Im klassischen Kunstgesang kommt es meist auf die Tragfähigkeit einer Stimme an. Sie soll über Glanz und Strahlkraft verfügen und sich durch ihren metallischer Klang auch gegen ein größeres Orchester durchsetzen. Beim ausgebildeten Sänger etwa klingt eine ganze Serie von hohen Obertönen verstärkt mit. Hier findet man im Spektrum einen stärker ausgeprägten Bereich von Frequenzen um 3000 Hz (F3 bis F5). Diesen Frequenzbereich nennt man deswegen den Sängerformanten. Im folgenden Hörbeispiel kann man den Unterschied zwischen einem Gesang ohne und einem solchen mit Sängerformant hören:
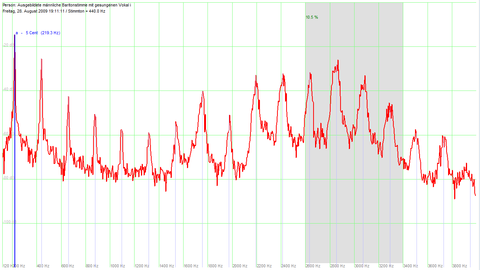
Die folgenden Abbildungen zeigen das Spektrum eines von einem Bariton gesungenen Tons (Tonhöhe ca. 220Hz)
mit den Vokalen /i/ bzw. /u/, einmal ohne und einmal mit Sängerformant.
Man beachte die Unterschiede in den Spektren im Bereich um 3000Hz.
| ohne Sängerformant | mit Sängerformant | Vokal i |  |
 |
|---|---|---|
| Vokal u | 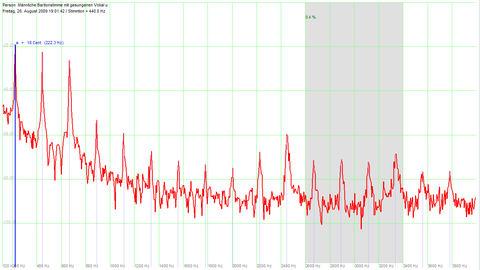 |
 |
4.2.4 Hüllkurven
Das Spektrum zeigt üblicherweise die Verteilung der Frequenzen einer Momentaufnahme eines Klanges (oder Mittelwert der Frequenzen über einen gewissen Zeitraum). Für die Klanganalyse in der Musik spielt aber gerade die zeitliche Veränderung eines Klanges eine entscheidende Rolle.
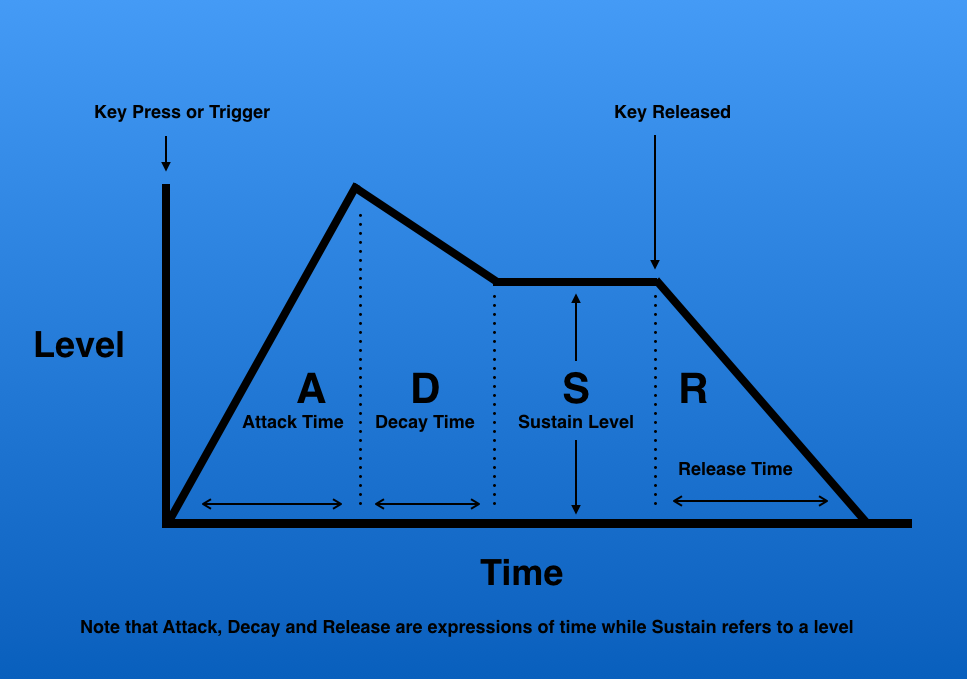
Bereits bei einem einzelnen Ton gibt es im allgemeinen einen zeitlichen Verlauf, beispielsweise in der Intensität des Klangs (und sogar in der Intensität der einzelnen Partialtöne). Dieser wird üblicherweise in Form einer Hüllkurve angegeben. Ein gebräuchliche, vereinfachte Form stellt die ADSR-Kurve dar. Diese unterscheidet bei einem Klang vier Phasen:
- Attack: Dauer des Anfangsanstiegs bis zum Maximum (z.B. nach Drücken einer Taste)
- Decay: Dauer des Abfalls bis zu einem konstanten Niveau
- Sustain: Höhe des konstanten Niveaus (Intensität, solange die Taste gedrückt gehalten wird)
- Release: Dauer des Abfalls nach Beendigung des Klangs (z.B. nach Loslassen einer Taste)
In dem folgenden Hörbeispiel erklingt die Aufnahme eines Bach-Chorals, gespielt auf einem Klavier. Es gibt nun drei Versionen: die Aufnahme wird
- normal,
- rückwärts (d.h. von hinten nach vorne),
- mit umgekehrter Hüllkurve
4.2.5 Spektrogramm
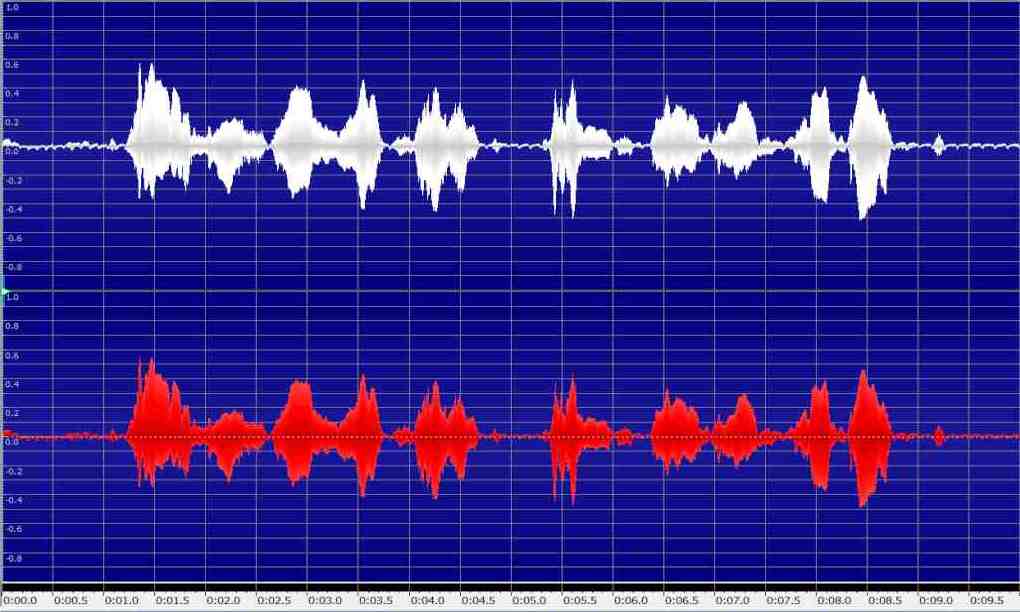
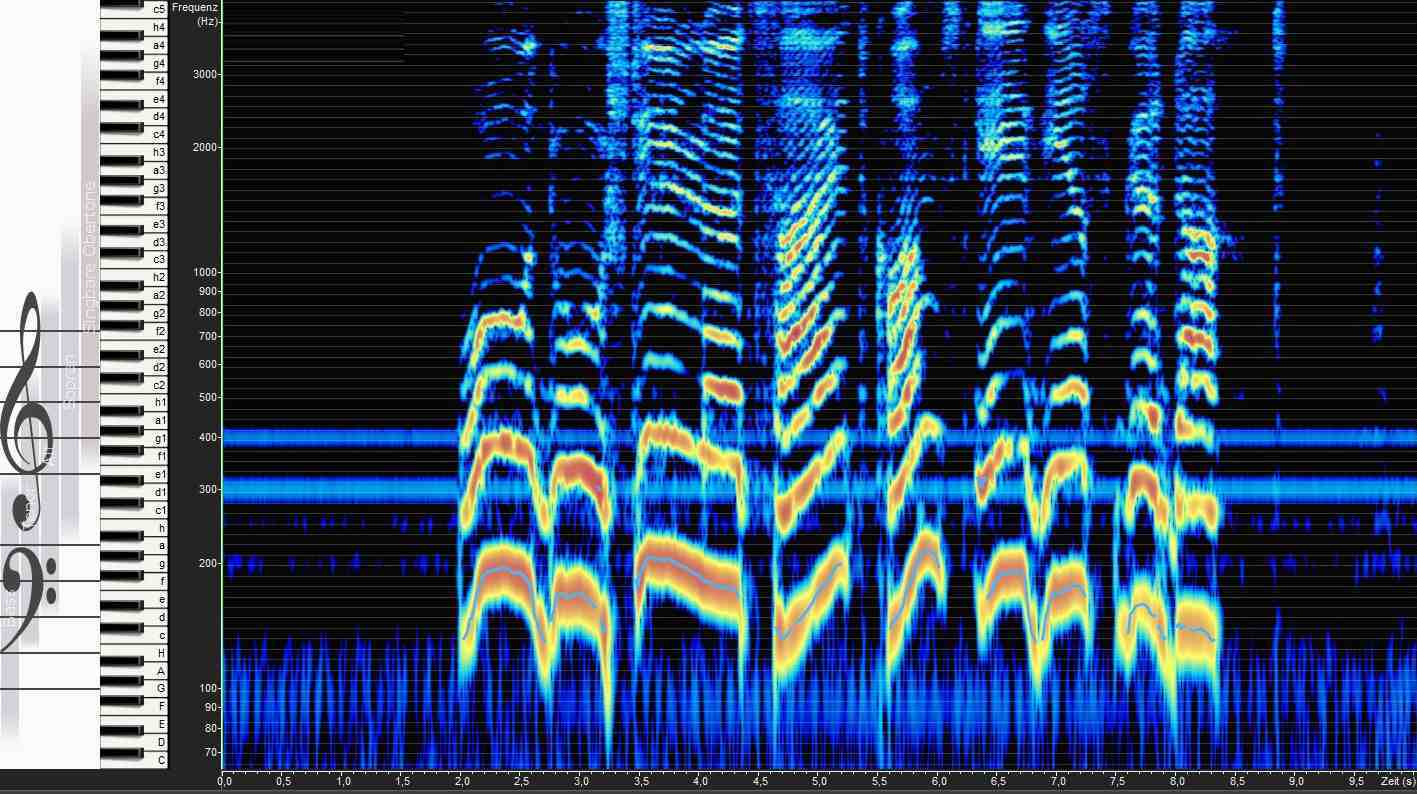
Neben der Betrachtung des zeitlichen Verlaufs eines einzelnen Klangereignisses ist in der Musik und vor allem auch in der Linguistik der zeitliche Verlauf einer Folge von Klangereignissen von Interesse. Bei einem sog. Spektrogramm (oder auch Sonagramm) wird die zeitliche Veränderung des Spektrums einer Schallquelle dargestellt. Man hat also drei Dimensionen: Frequenz, Amplitude und Zeit. Üblicherweise bildet die Zeit die X-Achse und die Frequenz die Y-Achse. Die Amplitude (Intensität) wird durch den Schwätzungsgrad bzw. die Farbcodierung repräsentiert.
Das folgende Beispiel zeigt die Schallwelle sowie das Spektrogramm zu dem (langsam) gesprochenen Text "O du stille Zeit, kommst eh wir's gedacht":